
My Thoughts on "Be Like a Goldfish, Don't Memorize!"
Training large language models (LLMs) on vast datasets is a double-edged sword. While we want them to learn general patterns, we must strictly avoid the verbatim memorization of sensitive data from the training corpus. A ‘24 NEURIPS paper titled “Be like a Goldfish, Don’t Memorize!” (Hans et al. 2024) introduces a surprisingly simple approach to address this issue: the Goldfish Loss.
The novel idea is to exclude specific tokens from the loss calculation during training, instead of incorporating all tokens up to the predicted one. This forces the model to learn general patterns rather than relying on rote memorization. Just like a goldfish with its famously short memory, this loss function forces the model to ‘forget’ specific tokens during training.1 Let’s first understand why this matters.
The Problem of Memorization
Memorization means that a generative model, like an LLM, fails to generalize and either copies or nearly replicates training samples in regions of the input space with poor coverage of training samples.2 Memorization in LLMs poses a severe risk to both LLM developers and data donors, whose data eventually end up in a training corpus. Risks brought up by the authors include:
- Copyright Risk for Providers/Customers: If a model memorizes lyrics, books, or copyrighted code, it can reproduce them verbatim, leading to uncertainties and potential lawsuits for those hosting the models and consuming the output. Recent practical examples include the lawsuit against Meta for training Llama 3 on Anna’s Archive and LibGen 3 or a lawsuit by German songwriter Helene Fischer (represented by GEMA) against OpenAI for memorizing the lyrics of “Atemlos durch die Nacht”4,5.
- Privacy Risks: Memorization in LLMs can also lead to leakage of personally identifiable or sensitive information. Remember the early days, when you could trick ChatGPT to leak real email footers and other personally identifiable information because the model had memorized them from the training corpus? 6
No wonder European regulators are increasingly pushing for measures to assess memorization. In my daily work at Atruvia, I also have to assess the risk of memorization, conduct analysis, and implement countermeasures for our own models. Let’s see if the Goldfish Loss could come to our rescue.
The Goldfish Loss
The authors propose Goldfish Loss (GL), a modification to the standard training objective used in Causal Language Modelling (CLM).
The Standard Causal Language Modelling Objective
Standard CLM trains the model to predict the next token given all previous tokens . Tokens are nowadays mostly sub-words; e.g., the tokenizer of GPT-4 would split Bilz into B, il, z.7 The loss is calculated for every token in the sequence of training tokens, where represents the model parameters:
The objective is minimized if the model correctly predicts the entire sequence with high confidence. What you should remember: all tokens contribute to the final loss.
Here’s a naive python implementation:
import torch
import torch.nn.functional as F
def compute_clm_loss(logits: torch.Tensor, tokens: torch.Tensor) -> torch.Tensor:
"""Compute standard CLM loss on all tokens.
Args:
logits (torch.Tensor): Model predictions [batch_size, seq_len, vocab_size]
tokens (torch.Tensor): Target tokens [batch_size, seq_len]
Returns:
torch.Tensor: loss.
"""
# Shift: predict token i+1 from tokens 0..i
shift_logits = logits[:, :-1, :].contiguous()
shift_labels = tokens[:, 1:].contiguous()
# Reshape for cross-entropy calculation
loss = F.cross_entropy(
shift_logits.view(-1, shift_logits.size(-1)),
shift_labels.view(-1)
)
return loss
Now we are all set for the Goldfish Loss.
The Goldfish Loss
The GL modifies this by randomly masking a subset of tokens during the loss calculation to mitigate verbatim generation of memorized training samples. Specifically, it drops of the tokens.
where is a binary mask. If , the token is ignored in the loss and contributes otherwise.
By intuition, hyperparameter controls the aggressiveness of masking. For very large values of , the GL approaches the standard CLM objective, since means almost no tokens are masked. In the paper the authors set , meaning 25% of all tokens are dropped.

Poor forgetful Dory
As for , the mask is pseudo-random, meaning that a passage is always masked in the same manner, unless the sequence is ever-so-slightly different.8 We will discuss in the next section how to arrive at such a mask.
For now, I’d like to stress the following aspects:
- Forward Pass: The model still sees all tokens in the context. It’s not masking like in BERT (Devlin et al. 2019) or tabular pre-training objectives like the of FT-Transformer (Gorishniy et al. 2021), where the input is corrupted. The input remains intact!
- Backward Pass: The loss is only computed for the unmasked tokens. The model is never explicitly penalized for failing to predict the masked tokens, so it doesn’t “learn” them as strongly. Critically, at inference time, the model must predict all tokens (including those that were masked during training). For identical sequences, the model must make an unsupervised guess for previously masked tokens, causing it to diverge from the training sequence and thereby impeding verbatim reproductions.
Here’s a python implementation, adapted from the author’s supplemental material 9:
import torch
import torch.nn.functional as F
def compute_goldfish_loss(logits: torch.Tensor, tokens: torch.Tensor, mask: torch.Tensor) -> torch.Tensor:
"""Compute Goldfish loss only on unmasked tokens.
Args:
logits (torch.Tensor): Model predictions [batch_size, seq_len, vocab_size]
tokens (torch.Tensor): Target tokens [batch_size, seq_len]
mask (torch.Tensor): Binary mask [batch_size, seq_len] (1 = compute loss, 0 = skip)
Returns:
torch.Tensor: loss.
"""
# Shift: predict token i+1 from tokens 0..i
shift_logits = logits[:, :-1, :].contiguous()
shift_labels = tokens[:, 1:].contiguous()
shift_mask = mask[:, 1:].contiguous()
# Reshape for cross-entropy calculation
loss = F.cross_entropy(
shift_logits.view(-1, shift_logits.size(-1)),
shift_labels.view(-1),
reduction='none' # Don't reduce yet ;)
)
# Apply mask and compute mean only over unmasked positions
mask_flat = shift_mask.view(-1)
masked_loss = loss * mask_flat
return masked_loss.sum() / mask_flat.sum()
The Hashed Mask
Let’s now focus on the token mask, the second main contribution of the paper.
Recall that most language models are trained on internet corpora and the internet is a fuzzy place10. Texts may be copied across the web (looking at you, BuzzFeed), may be embedded into larger texts, or restructured; data curation thus makes up a large part of the effort spent on LLM training.
Ideally, we’d like to mask the same passages identically to prevent leakage.
Naive approaches, like masking every -th token (referred to in the paper as static mask), don’t help much here, as the mask would be aligned to the pre-training sequence and deviate if the text were chunked or prefixed differently. Eventually, the model could see (and learn) every token. Feel free to experiment with the downsides of static masking in the interactive visualization.
Another naive idea could be to mask purely randomly. If masks were purely random (referred to as random mask in the paper), the model could learn every token over the course of several epochs or from differently masked duplicates, impeding our original goal.
Thus, we need a mask that is:
- deterministic
- independent from the absolute position of a sequence within a longer sequence
Hence, the authors propose a localized hashed mask. The decision to mask a token is deterministic based on its immediate preceding context (the previous tokens) and the output of a hash function . We mask (i.e., set ) if:
Note that with the context width , we introduce another hyperparameter that needs to be set carefully. An example from the paper makes this very clear: If is used, the model may never learn to produce the word “Power” at the end of the phrase “the Los Angeles Department of Water and Power.”. This would be highly undesirable. Equally, should not be too large, as then the hash is underdetermined for the first tokens in the document. In the reference implementation, the context width defaults to .
A nerdy implementation detail: You might wonder what happens to the first few tokens of a document. Since they don’t have enough preceding tokens to form a full context of size , we can’t compute a hash for them. Therefore, the first tokens are never masked (i.e., always included in the loss).
Now it’s your turn to play. Adjust the slider below to see how the parameter affects which tokens are masked. Adjust the text and suffixes. You can also switch between static mask and the hashed mask. I also recommend varying punctuation to see how it affects masking.
Here’s a Python implementation, adapted from the author’s reference implementation, which uses a performant hash-table-based approach 11.
import torch
# Initialize a global hash table (simulated)
TABLE_SIZE = 1_000_003 # Choose large prime
HASH_TABLE = torch.rand(TABLE_SIZE)
def generate_hashed_mask(tokens: torch.Tensor, k: int = 4, context_width: int = 4) -> torch.Tensor:
"""Generate deterministic mask using a hash table strategy.
Args:
tokens (torch.Tensor): Tensor of token IDs
k (int): Masking parameter (masks ~1/k of tokens). Defaults to 4.
context_width (int): Number of tokens in the context window (h). Defaults to 4.
Returns:
torch.Tensor: Binary mask tensor [seq_len] where 1 = compute loss, 0 = skip
"""
seq_len = tokens.size(0)
mask = torch.ones(seq_len) # Don't mask by default
# We can only mask if we have enough context
if seq_len < context_width:
return mask
# Create sliding windows of size 'context_width'
# Result shape: [num_windows, context_width]
windows = tokens.unfold(0, context_width, 1)
# Compute a hash for each window
window_hashes = windows.prod(dim=1) % TABLE_SIZE
random_values = HASH_TABLE[window_hashes]
# Determine which to drop: value < 1/k
# These correspond to tokens at indices [context_width-1, seq_len-1]
tokens_to_drop = random_values < (1.0 / k)
# Apply drops to the mask
# We offset by (context_width - 1) because the first window ends at index (context_width - 1)
mask[context_width-1:][tokens_to_drop] = 0.0
return mask
# Example usage
tokens = torch.tensor([101, 2054, 2003, 1037, 2003, 1037, 2003, 1037])
mask = generate_hashed_mask(tokens, k=4, context_width=4)
print(mask)
Two remarks on the code:
- Since the hash function is simply the product of token IDs modulo the table size, it is permutation-invariant (e.g.,
[1,2,3]and[2,3,1]produce the same hash). This leads to collisions, as reordered tokens within the same context produce the same hash. This may not always be desirable. Also, be aware of multiplying with token id . - The hash table should be reasonably large and of prime size.
Experiments & Results
The authors tested Goldfish Loss in diverse experiments w.r.t. memorization, training efficiency, generation quality, and robustness to adversarial attacks. For my humble blog post I’ll focus on the first three.
They distinguish between two setups:
- Extreme Setup (aka Recipe For Disaster 🤓): a Llama-2-7B model for 100 epochs on a small dataset of 100 English Wikipedia articles. Temperature set to . This setup is aimed to promote memorization.
- Standard Setup: A TinyLlama-1.1B model trained for 1 epoch. This time the training dataset consists of sequences from the RedPajamaV2 dataset and Wikipedia. Test samples from Wikipedia were duplicated several times and added in random locations to the training set to mimic data duplication. Once more they use greedy decoding.
- In both setups, the test sets consists of a subsample of training sequences, that have been split into a prefix and a length of tokens.
Memorization is quantified in terms of exact match (Carlini et al. 2023) and RougeL scores (Lin 2004):
- Exact match measures the LLM’s ability to reproduce a training sequence verbatim given a prefix/prompt of length with greedy decoding.
- RougeL scores quantify the longest common, but not necessarily consecutive, subsequence of tokens shared with the sequence from the training set.
Here’s an interactive comparison of how the two metrics differ:
Interactive ROUGE-L & Exact Match
Compare a reference sequence with a generated sequence to see how the metrics are calculated. The Longest Common Subsequence (LCS) used for ROUGE-L is highlighted in green.
Both metrics share the property that a score of indicates perfect memorization.
Memorization in the Extreme Setup
In the extreme setup, the Llama-2-7B model with:
- Standard Training: With standard loss, the model memorized 84/100 articles verbatim, which gives an exact match of , as shown in the figure below.
- Goldfish Loss (): The model trained with goldfish loss achieved a perfect score of exact match . The results for the RougeL metrics indicate that this model still memorizes subsequences, but the likelihood of getting very long subsequences correct decreases exponentially with the length of the subsequence.
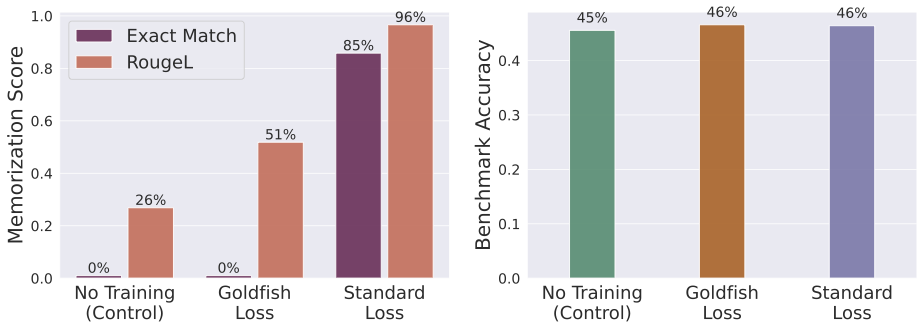
Memorization result for the extreme setup. Figure from Hans et al. (2024).
For the extreme setup, the authors are also able to show that sequences start to diverge at the index position where the first token has been dropped. This matches with our intuition from the unsupervised guess of dropped tokens 💪.
Memorization in the Standard Setup
In the standard setup, the goldfish loss still significantly reduces the model’s ability to reproduce training sequences compared to a model trained with standard CLM objective, as visualized in the figure below.
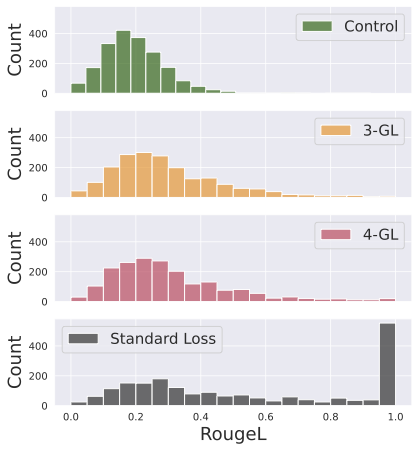
Memorization result in standard setup. Figure from Hans et al. (2024).
As evident from the graphics above, for low values (e.g., or ; fairly aggressive masking) the distribution of RougeL scores of models with goldfish loss are fairly similar to the control model, which was not trained on the test sequences at all. The high number of exact matches for the model with standard loss is concerning though.
I would have liked to see if they had also reported results for a setup where the training set is contaminated with near-duplicates that are hard to mask identically.
You might be wondering if the goldfish loss affects benchmark performance. In the paper the author’s evaluate two -GL models and compare against the model with standard loss and a control model (trained on RedPajamaV2 only) on selected tasks from the huggingface LLM leaderboard.
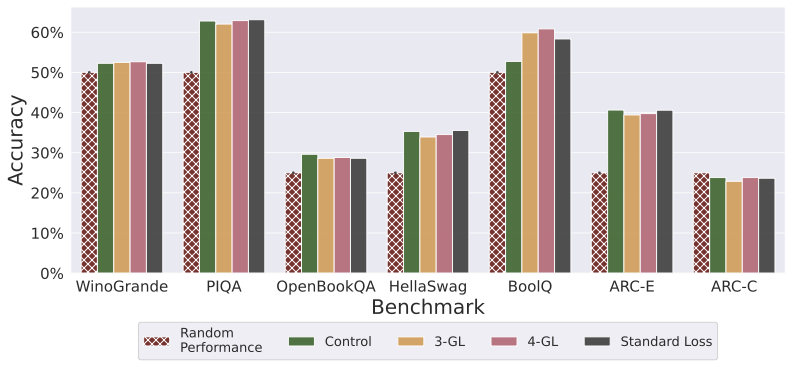
Benchmark Performance. Figure from Hans et al. (2024).
The results are visualized above. There seem to be no systematic differences between the overall performance of the control, standard loss, and any of the goldfish loss models.
Limitations
There are some caveats though:
- Training Efficiency: Since in a setup with goldfish loss, we are ignoring of the training tokens, the model learns “slower” per batch. You effectively need to train on more data (or for longer) to reach the same validation loss as a standard model. The authors, however, demonstrate (rather convincingly) on a RedPajamaV2 dataset, that if we compare the validation loss for the supervised tokens (aka unmasked) tokens with an equal number of input tokens in a standard training setup, both models end up with an approximately an equal validation loss. This can be seen below.
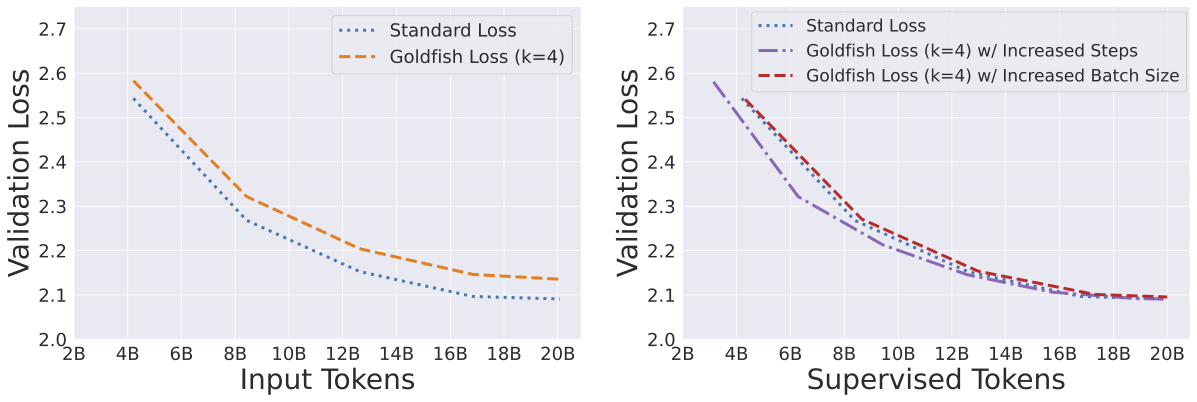
Validation loss comparison. Figure from Hans et al. (2024).
- Near-Duplicates: The approach is still prone to near-duplicates. You can spot this in the interactive visualization above easily. For example, small rewrites or some added punctuation or different unicode-encoding, the hashed mask might be different for each version, allowing the model to piece together the full text from the different copies.
My thoughts
The goldfish loss is a clever, lightweight adaption of the CLM that can be easily dropped into existing training recipes. This is a big plus for practitioners with limited resources.
It offers a promising alternative for training powerful models that respect privacy-by-design, rather than relying on complex machine unlearning strategies. I agree with the authors, that it’s most useful on high-risk sources or late phases of training e.g., fine-tuning.
In practice, the positive effects from the GL will only be as good as the engineering that went into normalization (see remarks in Sec. 3.1 of the paper), filtering and removal of near-duplicates of the training corpus. The common practice of training on rewritten synthetic texts or near-identical synthetic texts based on real seeds needs to be rethought, as both would impede consistent masking. 12
Lastly, I remain slightly skeptical about their copyright compliance angle:
We hope that goldfish loss paves the way for aiding copyright compliance rather than serving as a means to misuse private data maliciously. (Sec. 7)
While their loss function prevents verbatim reproduction, the model still learns the information and style from the copyrighted works. Is a paraphrased text more copyright-compliant? That’s a question for the courts, not the loss function.🪝
References
Carlini, Nicholas, Daphne Ippolito, Matthew Jagielski, Katherine Lee, Florian Tramer, and Chiyuan Zhang. 2023. Quantifying Memorization Across Neural Language Models. arXiv:2202.07646. arXiv. https://doi.org/10.48550/arXiv.2202.07646.
Devlin, Jacob, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. “BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding.” Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) (Minneapolis, MN) 1: 4171–86. https://doi.org/10.18653/v1/N19-1423.
Gorishniy, Yury, Ivan Rubachev, Valentin Khrulkov, and Artem Babenko. 2021. “Revisiting Deep Learning Models for Tabular Data.” Advances in Neural Information Processing Systems (Red Hook, NY) 34: 18932–43.
Hans, Abhimanyu, Yuxin Wen, Neel Jain, et al. 2024. Be Like a Goldfish, Don’t Memorize! Mitigating Memorization in Generative LLMs. arXiv:2406.10209. arXiv. https://doi.org/10.48550/arXiv.2406.10209.
Lin, Chin-Yew. 2004. “ROUGE: A Package for Automatic Evaluation of Summaries.” Text Summarization Branches Out (Barcelona, Spain), July, 74–81.
More than allegedly. As a child, I used to have a small goldfish living in a large bowl. ↩︎
While conceptually similar to overfitting, an overfitted model would fit the training distribution too precisely including noise and idiosyncrasies and perform poorly on the true underlying distribution. ↩︎
This article by the Atlantic gives a good overview incl. a search tool. ↩︎
Haters would say, that reproducing the lyrics verbatim isn’t too hard. ↩︎
Read this article for some background information on the attack vector. ↩︎
You can play around with different tokenizers on tiktokenizer.vercel.app. It’s also a nifty tool, if your models need to run on a tight budget. ↩︎
In this context, pseudo-random doesn’t refer to pseudo-random number generators (the most common variant in modern computers), but rather to the fact that masking of tokens is done randomly and identical sequences will be masked identically. If you are interested in true random number generators, you can read this article on a creative approach to generate truly random numbers using lava lamps at cloudflare. ↩︎
For some interesting infographics see this nature article ↩︎
For applications of these techniques see e.g., the technical report of Phi-4 ↩︎